
我相信大家在成為軟體工程師前
就有接觸excel來查閱或整理資料了~
在工作中看過奇怪的

在學完程式之前
應該不少人是透過手動操作來處理這個檔案資訊
但畢竟學到這邊的已經是優秀的工程師了
接下來我們就來實際體驗怎麼處理這個專案吧
等等會給大家幾個步驟地描述
讓大家身臨其境 彷彿真的進到這個專案需求內
顧客不會給你解答)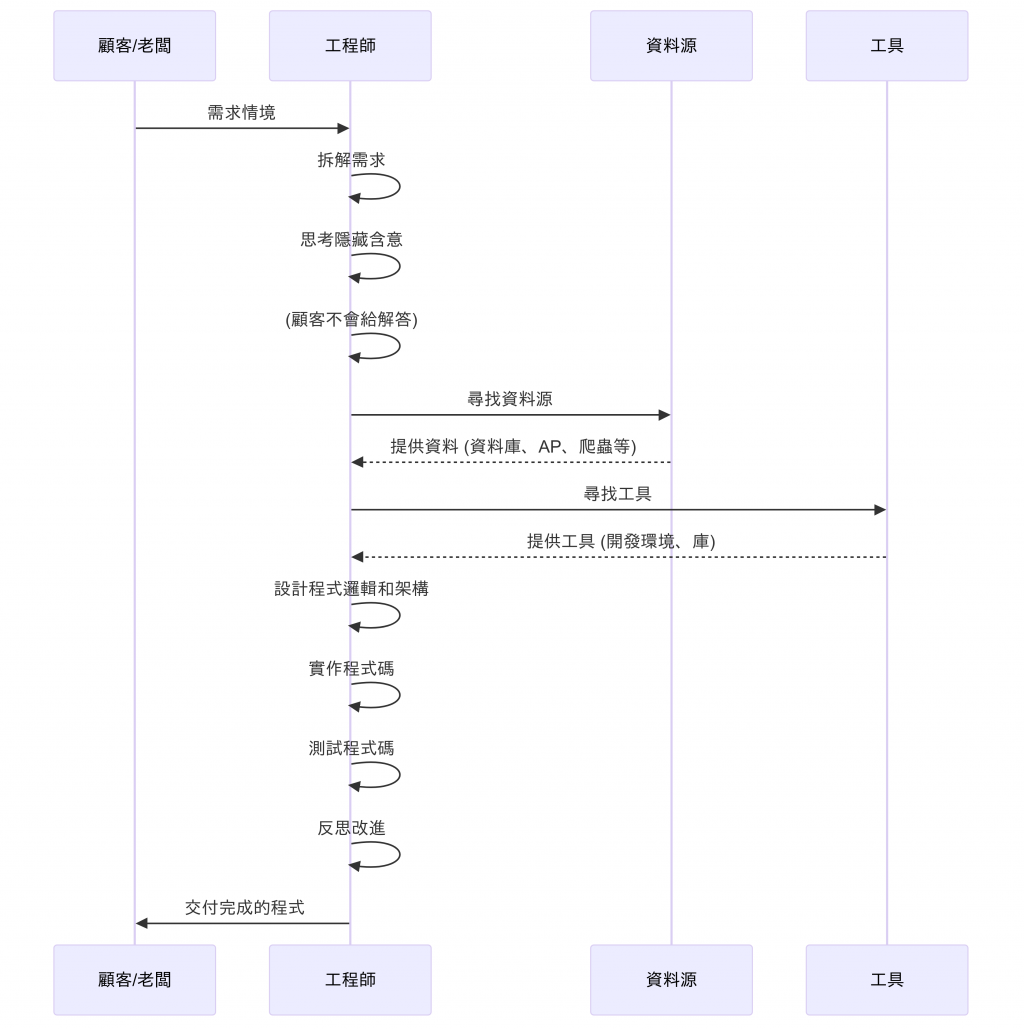
老闆跟你說需求的情境
老闆跟你討論,需要把顧客的資料整理
並且要按照顧客生日,每個quarter分類顧客資料,以利於通知顧客何時可以收到公司的贈品。
這一段話其實對工程師來說有非常多的訊息可以思考
比如說:
我們整理成**程式功能表格**就會變成這樣
| 問題 | 程式邏輯 |
|---|---|
| 1. 資料從何而來 | - 資料來源:顧客基本資料、顧客地址資料。- 資料格式:可讀格式(如 Excel、CSV 或資料庫)。 |
| 2. 整理時的挑戰 | - 資料清理: - 檢查重複值。 - 確認缺失值。 - 格式化資料。 - 資料過濾:清除不完整或無效的資料。 |
| 3. 合併資料的需求 | - 確保顧客ID一致性,避免資料錯誤。- 檢查合併後的資料完整性。 |
| 4. 功能順序 | 1. 讀取資料。2. 資料清理。3. 合併不同資料來源。4. 按生日分類顧客。5. 輸出結果至 Excel 文件。 |
| 5.錯誤影響 | - 錯誤的資料清理會影響後續合併和分類。- 錯誤合併可能導致顧客資料丟失或錯誤分類。 |
| 6. 分組後的整理 | - 可將資料分為多個工作表以便查閱。- 可考慮附加統計分析或可視化圖表以便直觀查看顧客分佈情況。 |
| 7. 其他考量點 | - 測試與驗證:定期檢查資料結果。- 文檔與紀錄:保持良好文檔紀錄。- 客戶隱私:遵循隱私法規。- 自動化:考慮將流程自動化以處理最新資料。 |
有沒有覺得,老闆的兩句話。員工or工程師要做的事情很多XDD
有的舉手(案讚)
假如我們今天從系統上下載的資料是這兩份
大家可以把它貼到excel上使用
| 縣市 | 鄉鎮區 | 地址 | 顧客ID |
|---|---|---|---|
| 台北市 | 中正區 | CUST1 | |
| 高雄市 | 三民區 | 民族一路 100 號 | CUST2 |
| 台中市 | 西屯區 | 台灣大道三段 120 號 | CUST3 |
| 新北市 | 板橋區 | 中山路 500 號 | CUST4 |
| 台南市 | 安平區 | 安平路 88 號 | CUST5 |
| 顧客ID | 顧客姓名 | 生 日 |
|---|---|---|
| CUST1 | 王小明 | 1990-01-01 |
| CUST2 | 李大華 | 1985-05-12 |
| CUST3 | 陳美麗 | 1992-08-20 |
| CUST4 | 林志玲 | 1978-11-05 |
| CUST5 | 張三豐 | 1965-02-28 |
透過上面的結果我們可以列一張功能表
讓工程師團隊可以把功能想法做出來
分成問題、住記、是否實作
| 問題 | 註記 | 是否實作 |
|---|---|---|
| 1. 資料從何而來 | - 兩份excel檔案(顧客通訊地址&顧客基本資料) | ✅ |
| 2. 整理時的挑戰 | -資料有缺通訊地址不完整 | ✅ |
| 3. 合併資料的需求 | - 需要把兩張excel處理後,合併 | ✅ |
| 4. 功能順序 | 1. 讀取資料。2. 資料清理。3. 合併不同資料來源。4. 按生日分類顧客。5. 輸出結果至 Excel 文件。 | ✅ |
| 5. 分組後的整理 | - 需要分類Q1~Q4的sheet | ✅ |
| 6. 錯誤處理功能 | - 暫時不需要 | ❌ |
| 7. 其他考量點 | - 測試與驗證:定期檢查資料結果。- 文檔與紀錄:保持良好文檔紀錄。- 客戶隱私:遵循隱私法規。- 自動化:考慮將流程自動化以處理最新資料。 | ✅&❌ (看心情) |
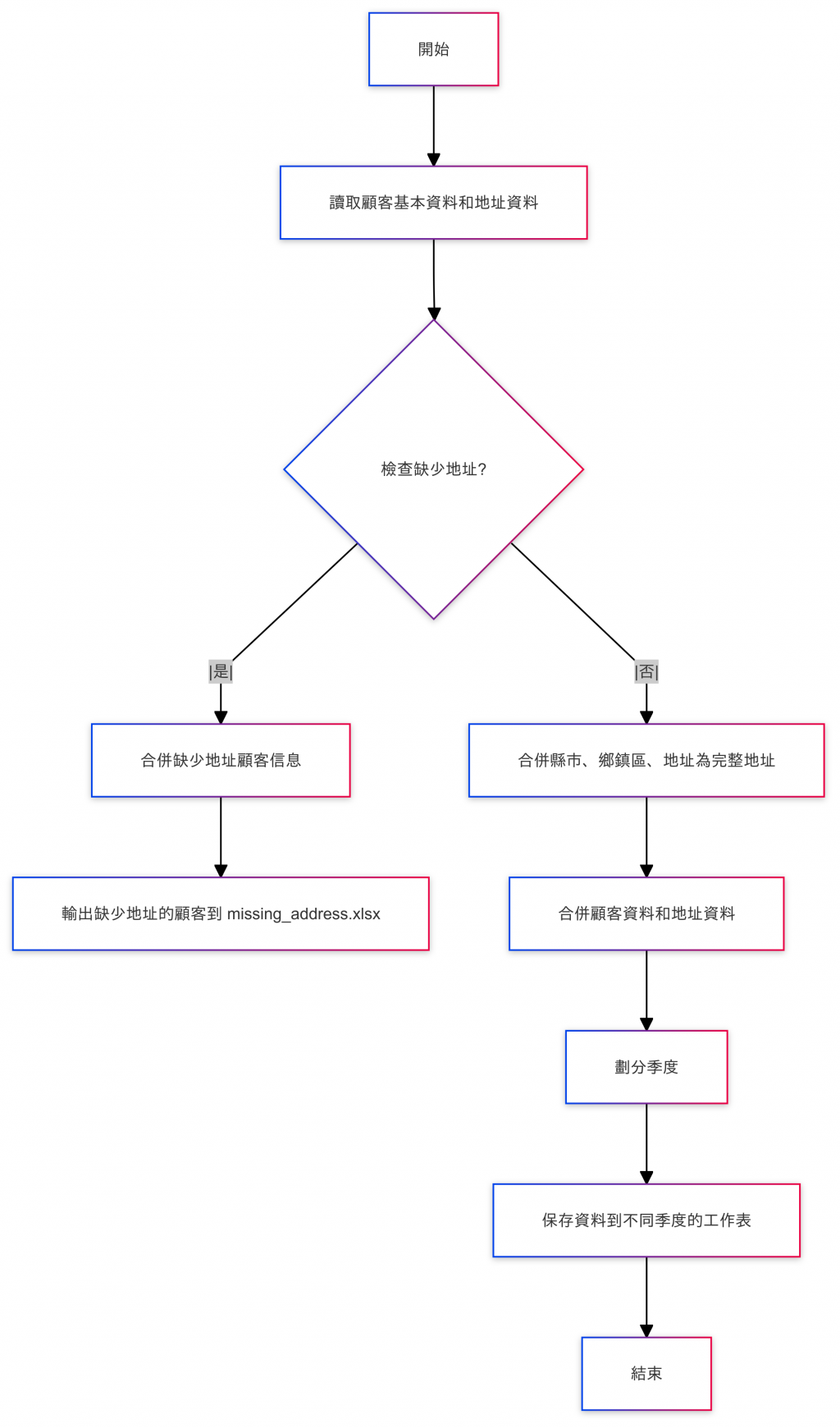
透過這張流程圖我們可以清楚的知道要怎麼開始動手實作程式碼
可以搭配時序圖拆解不同腳色跟功能的順序操作(user以及資料處理還有excel 寫入的功能模組)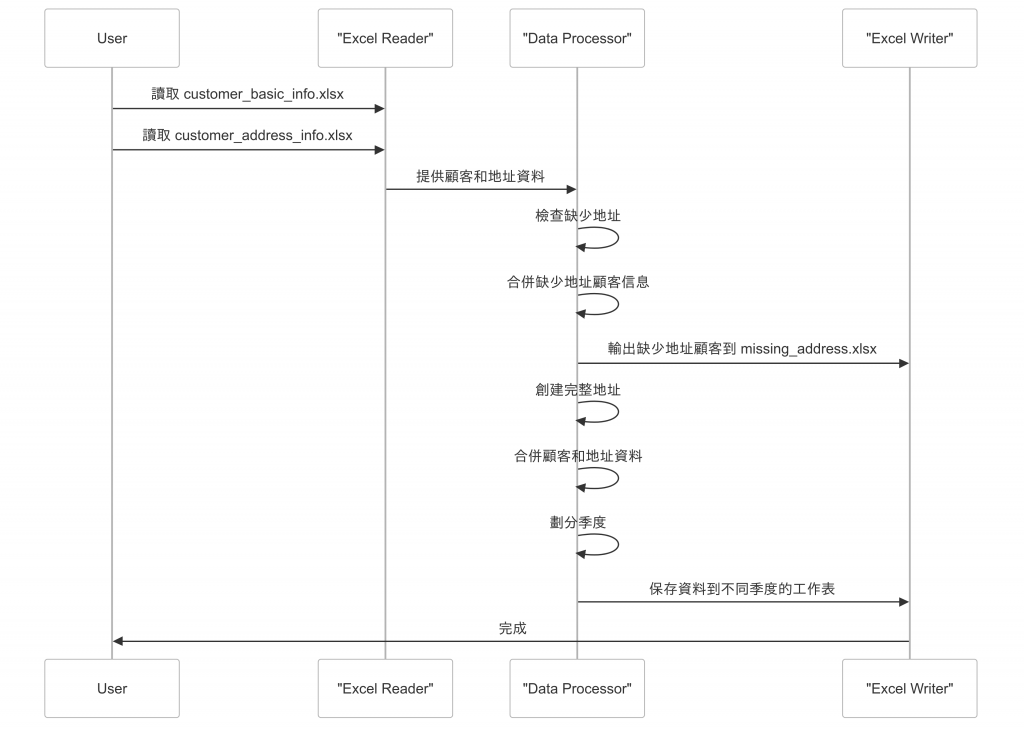
import pandas as pd
# 讀取顧客基本資料和地址資料
customer_df = pd.read_excel('customer_basic_info.xlsx') # 顧客基本資料
address_df = pd.read_excel('customer_address_info.xlsx') # 顧客地址
# 檢查是否有缺少「縣市」、「鄉鎮區」或「地址」的欄位
missing_address = address_df[address_df[['縣市', '鄉鎮區', '地址']].isnull().any(axis=1) |
(address_df[['縣市', '鄉鎮區', '地址']].applymap(str).applymap(str.strip) == '').any(axis=1)]
# 如果有缺少地址的顧客,進行通知並將結果輸出到 missing_address.xlsx
if not missing_address.empty:
missing_customer_info = pd.merge(missing_address[['顧客ID']], customer_df, on='顧客ID', how='left')
missing_customer_info.to_excel('missing_address.xlsx', index=False)
print("已通知缺少地址的顧客,詳細內容見 missing_address.xlsx")
# 將「縣市」、「鄉鎮區」、「地址」欄位合併成「完整地址」
address_df['完整地址'] = address_df['縣市'].fillna('') + address_df['鄉鎮區'].fillna('') + address_df['地址'].fillna('')
# 合併顧客基本資料和地址資料,根據顧客ID匹配
merged_df = pd.merge(customer_df, address_df[['顧客ID', '完整地址']], on='顧客ID', how='left')
# 根據顧客生日將其分配到不同的季度
def assign_quarter(birthdate):
month = birthdate.month
if month in [1, 2, 3]:
return 'Q1'
elif month in [4, 5, 6]:
return 'Q2'
elif month in [7, 8, 9]:
return 'Q3'
else:
return 'Q4'
# 將生日轉換為日期格式並劃分季度
merged_df['Quarter'] = pd.to_datetime(merged_df['生日']).apply(assign_quarter)
# 將顧客資料按照季度分開存到不同的工作表
with pd.ExcelWriter('customer_summary.xlsx', engine='openpyxl') as writer:
for quarter in ['Q1', 'Q2', 'Q3', 'Q4']:
quarter_df = merged_df[merged_df['Quarter'] == quarter]
if not quarter_df.empty:
quarter_df.to_excel(writer, sheet_name=quarter, index=False)
print("資料已成功整合並按季度分配到不同工作表中")
說明跟解釋比較複雜的程式碼區段
panda前面沒交到的function也會說明~~
missing_address = address_df[address_df[['縣市', '鄉鎮區', '地址']].isnull().any(axis=1) |
(address_df[['縣市', '鄉鎮區', '地址']].applymap(str).applymap(str.strip) == '').any(axis=1)]
使用any()搭配axis=1,以及applymap()的方式,這些都是用來檢查DataFrame中的數據是否存在缺失值或空字符串的。
any()與axis=1
any(axis=1):這個方法會沿著DataFrame的行(row)進行操作。在這種情況下,axis=1表示針對每一行進行檢查。這意味著如果該行中有任何一個元素為True,則整行的結果為True。
應用示例:例如,如果某一行的縣市、鄉鎮區或地址有缺失值(NaN),any(axis=1)會返回True,表示這一行滿足條件。
applymap()的使用
applymap(str):這個函數將str函數應用到DataFrame的每一個元素上,這裡的目的是將所有元素轉換為字符串類型,以確保後續操作的正確性。
applymap(str.strip):這一行用於去除每個字符串元素的前後空白。也就是說,如果某個欄位的值是空白字符串(例如" "),經過strip()處理後會變成空字符串""。
第一部分 (isnull().any(axis=1)):
檢查縣市、鄉鎮區、地址這幾個欄位中是否有NaN值。若存在,該行會被標記為需要處理的行。
第二部分 (applymap(str).applymap(str.strip) == ''):
將這些欄位中的值轉換為字符串並去掉空白後,檢查是否為空字符串。如果這些欄位的值為空字符串(如 ""),則該行同樣會被標記。
最終結果:
使用|(邏輯或)將兩個條件結合在一起,最終返回一個新的DataFramemissing_address,其中包含所有缺少縣市、鄉鎮區或地址的顧客資料。
if not missing_address.empty:
missing_customer_info = pd.merge(missing_address[['顧客ID']], customer_df, on='顧客ID', how='left')
missing_customer_info.to_excel('missing_address.xlsx', index=False)
print("已通知缺少地址的顧客,詳細內容見 missing_address.xlsx")
1. if not missing_address.empty:
missing_address.empty 檢查 missing_address 這個資料框是否為空。如果資料框內有任何一筆資料,empty 會返回 False,反之如果資料框內沒有資料,則會返回 True。
if not missing_address.empty: 意思是,如果 missing_address 不為空(即有顧客的地址資料缺失),就執行以下的程式。
2. missing_customer_info = pd.merge(missing_address[['顧客ID']], customer_df, on='顧客ID', how='left')
* pd.merge() 是 pandas 提供的用來合併兩個資料框的函數,類似於 SQL 的 JOIN 操作。
參數解析:
missing_address[['顧客ID']]: 從 missing_address 資料框中選擇 顧客ID 這一列,這列包含缺失地址的顧客 ID。
* customer_df: 這是另一個資料框,包含顧客的基本資訊(例如姓名、聯繫資訊等)。
on='顧客ID': 指定合併的鍵(key),這裡是 顧客ID,即根據這個欄位進行匹配合併。
* how='left': 表示左連接(Left Join),即保留 missing_address 中的所有 顧客ID,並從 customer_df 中提取匹配的顧客基本資料。
* 結果:這樣會生成一個新的資料框 missing_customer_info,其中包含缺失地址的顧客以及這些顧客的基本資訊。
3. missing_customer_info.to_excel('missing_address.xlsx', index=False)
to_excel() 函數將 missing_customer_info 這個資料框導出為一個 Excel 檔案。
index=False 表示在輸出 Excel 檔案時不需要包含 pandas 自動生成的索引列。
tips - pandas 的 merge() 函數:
pd.merge() 是 pandas 中的合併函數,類似 SQL 的 JOIN 操作,用來根據某一欄位(這裡是 顧客ID)將兩個資料框合併。它支持不同類型的合併方式,比如 left, right, inner, 和 outer join。
在這個例子中,使用了 left join,這種方式會保留 missing_address 中的所有顧客,即使 customer_df 中沒有對應的顧客記錄,也不會丟失這些顧客的 顧客ID。
總結:
這段程式碼的流程是:
1.找到缺少地址資料的顧客(missing_address)。
2.透過合併操作,將這些顧客的基本資料和 missing_address 的顧客 ID 匹配。
3.將這些缺少地址的顧客資料輸出到 Excel 檔案中。
4.印一個提示,通知資料已經成功輸出。
# 將「縣市」、「鄉鎮區」、「地址」欄位合併成「完整地址」並去除空格
address_df['完整地址'] = (address_df['縣市'].fillna('') +
address_df['鄉鎮區'].fillna('') +
address_df['地址'].fillna('')).str.strip() # 去除前後空格
這一段比較單純就是
此行在address_df中創建一個名為完整地址的新欄位,通過串聯三個地址相關欄位的值來實現,並用空字符串替換任何缺失值。
merged_df = pd.merge(customer_df, address_df[['顧客ID', '完整地址']], on='顧客ID', how='left')
此行根據顧客ID合併顧客和地址數據,包含新創建的完整地址欄位,結果存儲在merged_df中。
透過前面學到的if else可以把數字塞進去在return Q1~Q4
步驟1.使用 pd.to_datetime() 函數將「生日」欄位轉換為 datetime 格式,從而能夠輕鬆提取月份。
步驟2.自定義函數 assign_quarter() 根據月份來手動劃分季度,並通過 apply() 函數將其應用到每個顧客的生日上。
merged_df['Quarter'] = pd.to_datetime(merged_df['生日']).apply(assign_quarter)
這邊其實是透過panda的日期轉換才可以輕而易舉地把月份拆解出來
1.pd.to_datetime(merged_df['生日']):
很方便地使用 .month 屬性來提取生日的月份,這樣每個顧客的生日月份就可以用來計算他們所屬的季度。2.apply(assign_quarter):
apply() 是 pandas 的一個非常強大的函數,這裡,它將我們定義的 assign_quarter 函數應用到轉換為 datetime 格式的 生日 欄位上,並根據月份計算顧客所屬的季度。
tips補充panda apply好用的功能
這邊可以透過額外寫一個function邏輯
再透過apply()把資料丟進去運算回傳結果
import pandas as pd
# 建立一個資料框,包含姓名和台幣薪水
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'TWD Salary': [50000, 60000, 55000]
}
df = pd.DataFrame(data)
# 假設當前匯率 1 美金 = 30 台幣
exchange_rate = 30.0
# 定義一個將台幣轉換成美金的函數
def convert_to_usd(twd_salary):
return twd_salary / exchange_rate
# 使用 apply() 函數將轉換應用到每個台幣薪水
df['USD Salary'] = df['TWD Salary'].apply(convert_to_usd)
# 顯示結果
print(df)
這個範例就是很經典的
with pd.ExcelWriter('customer_summary.xlsx', engine='openpyxl') as writer:
for quarter in ['Q1', 'Q2', 'Q3', 'Q4']:
quarter_df = merged_df[merged_df['Quarter'] == quarter]
if not quarter_df.empty:
quarter_df.to_excel(writer, sheet_name=quarter, index=False)
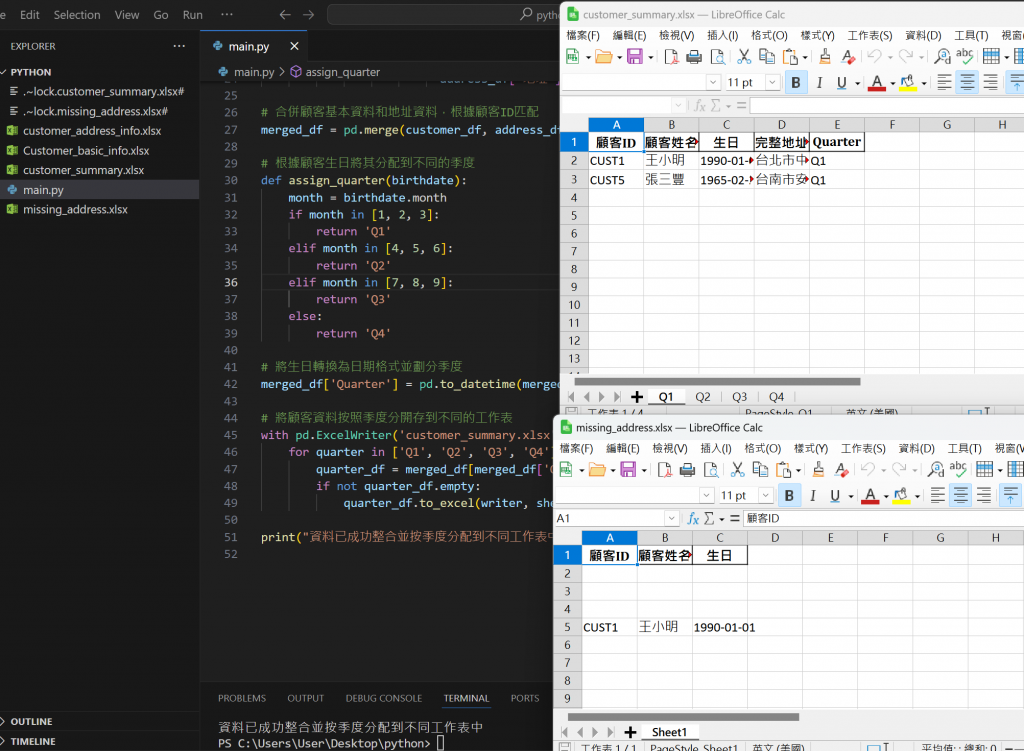
從這邊我們可以看到程式碼執行成功呢!!

今天如果老闆突然說~
很棒~那可以幫我把產生出來的表,如果是"台北市" 的客戶要標註黃色,因為是我們公司附近的客戶。
你可能會很想垂老闆
那~我們也只能修改程式碼了(哭)
其實前面感覺只有用到panda的功能
我們最後再補上openxl的PatternFill功能吧
修改的重點:
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
from openpyxl.styles import PatternFill
# 讀取顧客基本資料和地址資料
customer_df = pd.read_excel('customer_basic_info.xlsx') # 顧客基本資料
address_df = pd.read_excel('customer_address_info.xlsx') # 顧客地址
# 檢查是否有缺少「縣市」、「鄉鎮區」或「地址」的欄位
missing_address = address_df[address_df[['縣市', '鄉鎮區', '地址']].isnull().any(axis=1) |
(address_df[['縣市', '鄉鎮區', '地址']].applymap(str).applymap(str.strip) == '').any(axis=1)]
# 如果有缺少地址的顧客,進行通知並將結果輸出到 missing_address.xlsx
if not missing_address.empty:
missing_customer_info = pd.merge(missing_address[['顧客ID']], customer_df, on='顧客ID', how='left')
missing_customer_info.to_excel('missing_address.xlsx', index=False)
print("已通知缺少地址的顧客,詳細內容見 missing_address.xlsx")
# 將「縣市」、「鄉鎮區」、「地址」欄位合併成「完整地址」
address_df['完整地址'] = address_df['縣市'].fillna('') + address_df['鄉鎮區'].fillna('') + address_df['地址'].fillna('')
# 合併顧客基本資料和地址資料,根據顧客ID匹配
merged_df = pd.merge(customer_df, address_df[['顧客ID', '完整地址']], on='顧客ID', how='left')
# 根據顧客生日將其分配到不同的季度
def assign_quarter(birthdate):
month = birthdate.month
if month in [1, 2, 3]:
return 'Q1'
elif month in [4, 5, 6]:
return 'Q2'
elif month in [7, 8, 9]:
return 'Q3'
else:
return 'Q4'
# 將生日轉換為日期格式並劃分季度
merged_df['Quarter'] = pd.to_datetime(merged_df['生日']).apply(assign_quarter)
# 使用 openpyxl 來創建 Excel 文件並分配到不同的工作表
wb = Workbook()
for quarter in ['Q1', 'Q2', 'Q3', 'Q4']:
quarter_df = merged_df[merged_df['Quarter'] == quarter]
if not quarter_df.empty:
ws = wb.create_sheet(title=quarter)
# 在 Excel 中填寫資料
for r in dataframe_to_rows(quarter_df, index=False, header=True):
ws.append(r)
# 對於台北市的客戶,將行填滿顏色
for row in ws.iter_rows(min_row=2, max_row=ws.max_row, min_col=1, max_col=ws.max_column): # 忽略標題行
if row[3].value and '台北市' in row[3].value.strip(): # 假設「完整地址」在第 4 列(根據實際情況修改)
for cell in row:
cell.fill = PatternFill(start_color="FFFF00", end_color="FFFF00", fill_type="solid") # 設置為黃色
# 刪除預設的工作表
if 'Sheet' in wb.sheetnames:
std = wb['Sheet']
wb.remove(std)
# 儲存 Excel 文件
wb.save('customer_summary.xlsx')
print("資料已成功整合並按季度分配到不同工作表中,台北市的客戶已標記為黃色")
tips openxl創建文件跟填塞的功能
區段一 開啟workbook跟塞入資料
這段程式碼主要是在生成一個包含不同季度(Q1、Q2、Q3、Q4)顧客資料的 Excel 檔案。
wb = Workbook()
這一行初始化了一個新的 Excel 工作簿(Workbook)。Workbook 是 openpyxl 提供的類,用於創建和管理 Excel 檔案。
for quarter in ['Q1', 'Q2', 'Q3', 'Q4']:
這是一個循環,遍歷四個季度 ['Q1', 'Q2', 'Q3', 'Q4']。我們會針對每個季度來創建一個對應的工作表,並將相應季度的顧客資料寫入其中。
quarter_df = merged_df[merged_df['Quarter'] == quarter]
這一行從合併後的資料框 merged_df 中篩選出對應於當前季度(quarter)的顧客資料。merged_df 之前應該已經將顧客的生日根據月份分成了不同的季度(Q1-Q4)。這裡使用 Pandas 的條件過濾功能,篩選出屬於當前 quarter 的資料。
if not quarter_df.empty:
這是個判斷條件,如果 quarter_df 非空,則執行接下來的操作。如果沒有資料(即 quarter_df 是空的),這個季度的工作表將不會創建。
ws = wb.create_sheet(title=quarter)
這一行會為當前的季度創建一個新的工作表,並以當前的季度名稱(例如 Q1、Q2)作為標題。
for r in dataframe_to_rows(quarter_df, index=False, header=True):
這個循環會將 quarter_df 的內容轉換為行。dataframe_to_rows 是 openpyxl 提供的一個實用函數,它會將 Pandas 的資料框(DataFrame)轉換成可用於 Excel 的行數據。這裡的 index=False 是指不寫入 Pandas 的索引,header=True 是指將資料框的列名作為 Excel 表頭。
ws.append(r)
這一行會將每一行的資料寫入當前工作表 ws 中。
if 'Sheet' in wb.sheetnames:
std = wb['Sheet']
wb.remove(std)
這個功能會把創建時預設的sheet刪除。
區段二- 填顏色
1.ws.iter_rows() 是 openpyxl 提供的函數
用於逐行迭代 Excel 工作表的內容。這裡設定了 min_row=2 是為了跳過標題行,max_row=ws.max_row 則迭代至最後一行。min_col 和 max_col 設定了要遍歷的列範圍。
2.if row[3].value and '台北市' in row[3].value.strip():
這行是條件判斷,檢查這一行的第四列(完整地址列)是否包含 "台北市"。strip() 是用來移除可能的前後空白字元,避免因空格導致錯誤判斷。
3.如果條件成立,則進入下一個循環,for cell in row:
遍歷該行的每個儲存格,並用 PatternFill 設置其背景顏色為黃色(start_color="FFFF00",end_color="FFFF00",fill_type="solid")。
這段程式碼的主要步驟是:
1.創建一個新的 Excel 檔案。
2.將顧客資料按照季度分組並存入不同的工作表。
3.如果某個顧客的地址屬於 "台北市",則將該行的背景設置為黃色。
4.刪除初始空白工作表。
5.儲存結果為 customer_summary.xlsx。
今天的重點也很多~
雖然看起來是一段不到100行的程式碼
但是也讓大家看到了軟體工程師團隊跟老闆/客戶的溝通處
今天我們也學會了
的情況~
希望大家可以更好,共勉之!!
希望把程式碼真實情境變成故事一樣的拆分章節去解決!!


 iThome鐵人賽
iThome鐵人賽